1. 数据系统架构中的权衡
没有完美的解决方案,只有权衡取舍。[…] 你能做的就是努力获得最佳的权衡,这就是你所能期望的一切。
Thomas Sowell,接受 Fred Barnes 采访(2005)
早期读者注意事项
通过 Early Release 电子书,你可以在最早阶段读到作者写作中的原始、未编辑内容,从而在正式版发布前尽早使用这些技术。
这将是最终书籍的第 1 章。本书的 GitHub 仓库是 https://github.com/ept/ddia2-feedback。 如果你希望积极参与本草稿的审阅与评论,请在 GitHub 上联系。
数据是当今应用开发的核心。随着 Web 与移动应用、软件即服务(SaaS)和云服务普及,把许多不同用户的数据存放在共享的服务器端数据基础设施中,已经成为常态。来自用户行为、业务交易、设备与传感器的数据,需要被存储并可用于分析。用户每次与应用交互,既会读取已有数据,也会产生新数据。
当数据量较小、可在单机存储和处理时,问题往往并不复杂。但随着数据规模或查询速率增长,数据必须分布到多台机器上,挑战随之而来。随着需求变得更复杂,仅靠单一系统通常已不足够,你可能需要组合多个具备不同能力的存储与处理系统。
如果“管理数据”是开发过程中的主要挑战之一,我们称这样的应用为 数据密集型(data-intensive) 应用 1。与之对照,在 计算密集型(compute-intensive) 系统中,难点是并行化超大规模计算;而在数据密集型应用中,我们更常关心的是:如何存储与处理海量数据、如何管理数据变化、如何在故障与并发下保持一致性,以及如何让服务保持高可用。
这类应用通常由若干标准构件搭建而成,每个构件负责一种常见能力。例如,很多应用都需要:
- 存储数据,以便它们或其他应用程序以后能再次找到(数据库)
- 记住昂贵操作的结果,以加快读取速度(缓存)
- 允许用户按关键字搜索数据或以各种方式过滤数据(搜索索引)
- 一旦事件和数据变更发生就立即处理(流处理)
- 定期处理累积的大量数据(批处理)
在构建应用时,我们通常会选择若干软件系统或服务(例如数据库或 API),再用应用代码把它们拼接起来。如果你的需求恰好落在这些系统的设计边界内,这并不困难。
但当应用目标更有野心时,问题就会出现。数据库有很多种,各自特性不同、适用场景也不同,如何选型?缓存有多种做法,搜索索引也有多种构建方式,如何权衡?当单个工具无法独立完成目标时,如何把多个工具可靠地组合起来?这些都并不简单。
本书正是用来帮助你做这类决策:该用什么技术、怎样组合技术。你会看到,没有哪种方案在根本上永远优于另一种;每种方案都有得失。通过本书,你将学会提出正确问题来评估和比较数据系统,从而为你的具体应用找到更合适的方案。
我们将从今天组织内数据的典型使用方式开始。这些思想很多源自 企业软件(即大型组织的软件需求与工程实践,例如大公司和政府机构),因为在历史上,只有这类组织才有足够大的数据规模,值得投入复杂技术方案。如果你的数据足够小,电子表格都可能够用;但近些年,小公司和初创团队构建数据密集型系统也越来越常见。
数据系统的核心难点之一在于:不同的人需要用同一份数据做完全不同的事。在公司里,你和你的团队有自己的优先级,另一个团队即使使用同一数据集,目标也可能完全不同。更麻烦的是,这些目标往往并未被明确表达,容易引发误解和分歧。
为了帮助你了解可以做出哪些选择,本章比较了几个对比概念,并探讨了它们的权衡:
- 事务型系统和分析型系统之间的区别(“分析型与事务型系统”);
- 云服务和自托管系统的利弊(“云服务与自托管”);
- 何时从单节点系统转向分布式系统(“分布式与单节点系统”);以及
- 平衡业务需求和用户权利(“数据系统、法律与社会”)。
此外,本章还会引入贯穿全书的关键术语。
术语:前端和后端
本书讨论的大部分内容都与 后端开发 相关。对 Web 应用而言,运行在浏览器中的客户端代码称为 前端,处理用户请求的服务器端代码称为 后端。移动应用也类似前端:它们提供用户界面,通常经由互联网与服务器端后端通信。前端有时会在设备本地管理数据 2,但更棘手的数据基础设施问题通常发生在后端:前端只处理单个用户的数据,而后端需要代表 所有 用户管理数据。
后端服务通常通过 HTTP(有时是 WebSocket)提供访问。其核心是应用代码:在一个或多个数据库中读写数据,并按需接入缓存、消息队列等其他系统(可统称为 数据基础设施)。应用代码往往是 无状态 的:处理完一个 HTTP 请求后,不保留该请求上下文。因此,凡是需要跨请求持久化的信息,都必须写在客户端,或写入服务器端数据基础设施。
分析型与事务型系统
如果你在企业中从事数据系统工作,往往会遇到几类不同的数据使用者。第一类是 后端工程师,他们构建服务来处理读取与更新数据的请求;这些服务通常直接面向外部用户,或通过其他服务间接提供能力(参见“微服务与无服务器”)。有时服务也只供组织内部使用。
除了管理后端服务的团队外,通常还有两类人需要访问组织的数据:业务分析师,他们生成关于组织活动的报告,以帮助管理层做出更好的决策(商业智能 或 BI);以及 数据科学家,他们在数据中寻找新的见解,或创建由数据分析和机器学习(AI)支持的面向用户的产品功能(例如,电子商务网站上的“购买了 X 的人也购买了 Y”推荐、风险评分或垃圾邮件过滤等预测分析,以及搜索结果排名)。
尽管业务分析师和数据科学家倾向于使用不同的工具并以不同的方式操作,但他们有一些共同点:两者都执行 分析,这意味着他们查看用户和后端服务生成的数据,但他们通常不修改这些数据(除了可能修复错误)。他们可能创建派生数据集,其中原始数据已经以某种方式处理过。这导致了两种类型系统之间的分离——我们将在本书中使用这种区别:
- 事务型系统 由后端服务和数据基础设施组成,在这里创建数据,例如通过服务外部用户。在这里,应用程序代码基于用户执行的操作读取和修改其数据库中的数据。
- 分析型系统 服务于业务分析师和数据科学家的需求。它们包含来自事务型系统的只读数据副本,并针对分析所需的数据处理类型进行了优化。
正如我们将在下一节中看到的,事务型系统和分析型系统通常出于充分的理由而保持分离。随着这些系统的成熟,出现了两个新的专业角色:数据工程师 和 分析工程师。数据工程师是知道如何集成事务型系统和分析型系统的人,并更广泛地负责组织的数据基础设施 3。分析工程师对数据进行建模和转换,使其对组织中的业务分析师和数据科学家更有用 4。
许多工程师只专注于事务型或分析型其中一侧。然而,本书会同时覆盖这两类数据系统,因为它们都在组织内的数据生命周期中扮演关键角色。我们将深入讨论向内外部用户提供服务所需的数据基础设施,帮助你更好地与“另一侧”的同事协作。
事务处理与分析的特征
在商业数据处理的早期,对数据库的写入通常对应于发生的 商业交易(commercial transaction):进行销售、向供应商下订单、支付员工工资等。随着数据库扩展到不涉及金钱交换的领域,事务(transaction) 这个术语仍然保留了下来,指的是形成逻辑单元的一组读取和写入。
Note
第 8 章 详细探讨了我们所说的事务的含义。本章松散地使用该术语来指代低延迟的读取和写入。
尽管数据库开始用于许多不同类型的数据——社交媒体上的帖子、游戏中的移动、地址簿中的联系人等等——但是基本的访问模式仍然类似于处理商业交易。事务型系统通常通过某个键查找少量记录(这称为 点查询)。基于用户的输入插入、更新或删除记录。因为这些应用程序是交互式的,这种访问模式被称为 联机事务处理(OLTP)。
然而,数据库也越来越多地用于分析,与 OLTP 相比,分析具有非常不同的访问模式。通常,分析查询会扫描大量记录,并计算聚合统计信息(如计数、求和或平均值),而不是将单个记录返回给用户。例如,连锁超市的业务分析师可能想要回答以下分析查询:
- 我们每家商店在一月份的总收入是多少?
- 在我们最近的促销期间,我们比平时多卖出了多少香蕉?
- 哪个品牌的婴儿食品最常与 X 品牌尿布一起购买?
这些类型的查询产生的报告对商业智能很重要,可以帮助管理层决定下一步做什么。为了将这种使用数据库的模式与事务处理区分开来,它被称为 联机分析处理(OLAP)5。OLTP 和分析之间的区别并不总是很明确,但表 1-1 列出了一些典型特征。
表 1-1. 事务型系统和分析型系统特征比较
| 属性 | 事务型系统(OLTP) | 分析型系统(OLAP) |
|---|---|---|
| 主要读取模式 | 点查询(通过键获取单个记录) | 对大量记录进行聚合 |
| 主要写入模式 | 创建、更新和删除单个记录 | 批量导入(ETL)或事件流 |
| 人类用户示例 | Web 或移动应用程序的最终用户 | 内部分析师,用于决策支持 |
| 机器使用示例 | 检查操作是否被授权 | 检测欺诈/滥用模式 |
| 查询类型 | 固定的查询集,由应用程序预定义 | 分析师可以进行任意查询 |
| 数据代表 | 数据的最新状态(当前时间点) | 随时间发生的事件历史 |
| 数据集大小 | GB 到 TB | TB 到 PB |
Note
OLAP 中 联机(online) 的含义不明确;它可能指的是查询不仅用于预定义的报告,也可能是指分析师交互式地使用 OLAP 系统来进行探索性查询。
在事务型系统中,通常不允许用户构建自定义 SQL 查询并在数据库上运行它们,因为这可能会允许他们读取或修改他们没有权限访问的数据。此外,他们可能编写执行成本高昂的查询,从而影响其他用户的数据库性能。出于这些原因,OLTP 系统主要运行嵌入到应用程序代码中的固定查询集,只偶尔使用一次性的自定义查询来进行维护或故障排除。另一方面,分析数据库通常让用户可以自由地手动编写任意 SQL 查询,或使用 Tableau、Looker 或 Microsoft Power BI 等数据可视化或仪表板工具自动生成查询。
还有一种类型的系统是为分析型的工作负载(对许多记录进行聚合的查询)设计的,但嵌入到面向用户的产品中。这一类别被称为 产品分析 或 实时分析,为这种用途设计的系统包括 Pinot、Druid 和 ClickHouse 6。
数据仓库
起初,相同的数据库既用于事务处理,也用于分析查询。SQL 在这方面相当灵活:它对两种类型的查询都很有效。然而,在 20 世纪 80 年代末和 90 年代初,企业有停止使用其 OLTP 系统进行分析目的的趋势,转而在单独的数据库系统上运行分析。这个单独的数据库被称为 数据仓库。
一家大型企业可能有几十个甚至上百个联机事务处理系统:为面向客户的网站提供动力的系统、控制实体店中的销售点(收银台)系统、跟踪仓库中的库存、规划车辆路线、管理供应商、管理员工以及执行许多其他任务。这些系统中的每一个都很复杂,需要一个团队来维护它,因此这些系统最终主要是相互独立地运行。
出于几个原因,业务分析师和数据科学家直接查询这些 OLTP 系统通常是不可取的:
- 感兴趣的数据可能分布在多个事务型系统中,使得在单个查询中组合这些数据集变得困难(称为 数据孤岛 的问题);
- 适合 OLTP 的模式和数据布局不太适合分析(参见“星型和雪花型:分析模式”);
- 分析查询可能相当昂贵,在 OLTP 数据库上运行它们会影响其他用户的性能;以及
- 出于安全或合规原因,OLTP 系统可能位于不允许用户直接访问的单独网络中。
相比之下,数据仓库 是一个单独的数据库,分析师可以随心所欲地查询,而不会影响 OLTP 操作 7。正如我们将在第 4 章中看到的,数据仓库通常以与 OLTP 数据库非常不同的方式存储数据,以优化分析中常见的查询类型。
数据仓库包含公司中所有各种 OLTP 系统中数据的只读副本。数据从 OLTP 数据库中提取(使用定期数据转储或连续更新流),转换为分析友好的模式,进行清理,然后加载到数据仓库中。这种将数据导入数据仓库的过程称为 提取-转换-加载(ETL),如图 1-1 所示。有时 转换 和 加载 步骤的顺序会互换(即,先加载,再在数据仓库中进行转换),从而产生 ELT。
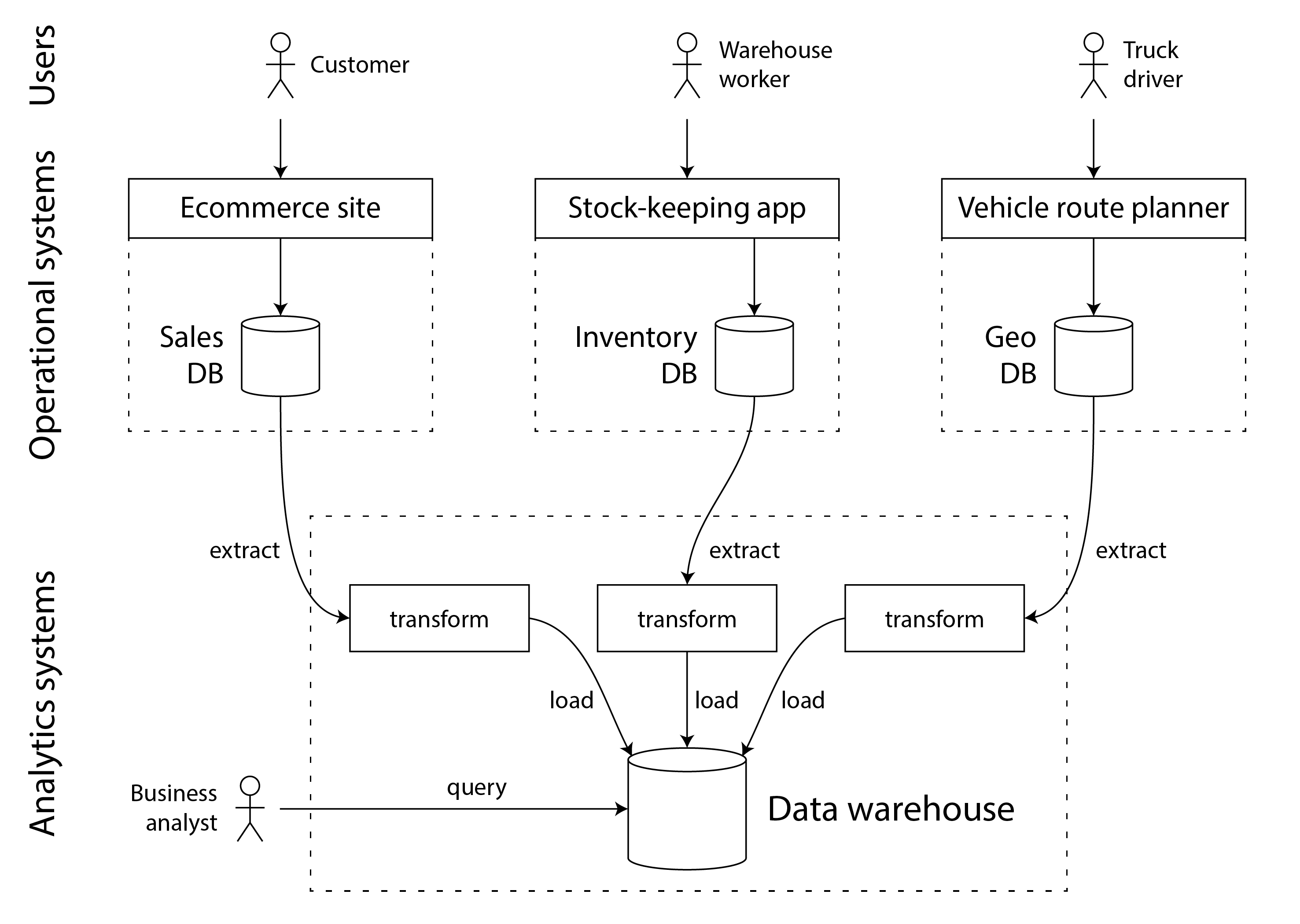
在某些情况下,ETL 过程的数据源是外部 SaaS 产品,如客户关系管理(CRM)、电子邮件营销或信用卡处理系统。在这些情况下,你无法直接访问原始数据库,因为它只能通过软件供应商的 API 访问。将这些外部系统的数据导入你自己的数据仓库可以实现通过 SaaS API 无法实现的分析。SaaS API 的 ETL 通常由专门的数据连接器服务(如 Fivetran、Singer 或 AirByte)实现。
一些数据库系统提供 混合事务/分析处理(HTAP),目标是在单个系统中同时支持 OLTP 和分析,而无需从一个系统 ETL 到另一个系统 8 9。然而,许多 HTAP 系统内部由一个 OLTP 系统与一个单独的分析系统耦合组成,隐藏在公共接口后面——因此两者之间的区别对于理解这些系统如何工作仍然很重要。
此外,尽管 HTAP 已出现,但由于目标和约束不同,事务型系统与分析型系统分离仍很常见。尤其是,让每个事务型系统拥有自己的数据库通常被视为良好实践(参见“微服务与无服务器”),这会形成数百个相互独立的事务型数据库;与之对应,企业往往只有一个统一的数据仓库,以便分析师能在单个查询里组合多个事务型系统的数据。
因此,HTAP 不会取代数据仓库。相反,它在同一应用程序既需要执行扫描大量行的分析查询,又需要以低延迟读取和更新单个记录的场景中很有用。例如,欺诈检测可能涉及此类工作负载 10。
事务型系统和分析型系统之间的分离是更广泛趋势的一部分:随着工作负载变得更加苛刻,系统变得更加专业化并针对特定工作负载进行优化。通用系统可以舒适地处理小数据量,但规模越大,系统往往变得越专业化 11。
从数据仓库到数据湖
数据仓库通常使用通过 SQL 进行查询的 关系 数据模型(参见第 3 章),可能使用专门的商业智能软件。这个模型很适合业务分析师需要进行的查询类型,但不太适合数据科学家的需求,他们可能需要执行以下任务:
- 将数据转换为适合训练机器学习模型的形式;这通常需要将数据库表的行和列转换为称为 特征 的数值向量或矩阵。以最大化训练模型性能的方式执行这种转换的过程称为 特征工程,它通常需要难以用 SQL 表达的自定义代码。
- 获取文本数据(例如,产品评论)并使用自然语言处理技术尝试从中提取结构化信息(例如,作者的情感或他们提到的主题)。同样,他们可能需要使用计算机视觉技术从照片中提取结构化信息。
尽管已经有人在努力将机器学习算子添加到 SQL 数据模型 12 并在关系基础上构建高效的机器学习系统 13,但许多数据科学家不喜欢在数据仓库等关系数据库中工作。相反,许多人更喜欢使用 Python 数据分析库(如 pandas 和 scikit-learn)、统计分析语言(如 R)和分布式分析框架(如 Spark)14。我们将在“数据框、矩阵和数组”中进一步讨论这些。
因此,组织面临着以适合数据科学家使用的形式提供数据的需求。答案是 数据湖:一个集中的数据存储库,保存任何可能对分析有用的数据副本,通过 ETL 过程从事务型系统获得。与数据仓库的区别在于,数据湖只是包含文件,而不强制任何特定的文件格式或数据模型。数据湖中的文件可能是数据库记录的集合,使用 Avro 或 Parquet 等文件格式编码(参见第 5 章),但它们同样可以包含文本、图像、视频、传感器读数、稀疏矩阵、特征向量、基因组序列或任何其他类型的数据 15。除了更灵活之外,这通常也比关系数据存储更便宜,因为数据湖可以使用商品化的文件存储,如对象存储(参见“云原生系统架构”)。
ETL 过程已经泛化为 数据管道,在某些情况下,数据湖已成为从事务型系统到数据仓库路径上的中间站。数据湖包含事务型系统产生的“原始”形式的数据,没有转换为关系数据仓库模式。这种方法的优势在于,每个数据消费者都可以将原始数据转换为最适合其需求的形式。它被称为 寿司原则:“原始数据更好”16。
除了从数据湖加载数据到单独的数据仓库之外,还可以直接在数据湖中的文件上运行典型的数据仓库工作负载(SQL 查询和业务分析),以及数据科学和机器学习的工作负载。这种架构被称为 数据湖仓,它需要一个查询执行引擎和一个元数据(例如,模式管理)层来扩展数据湖的文件存储 17。
Apache Hive、Spark SQL、Presto 和 Trino 是这种方法的例子。
超越数据湖
随着分析实践的成熟,组织越来越重视分析系统与数据管道的管理和运维,这一点在 DataOps 宣言中已有体现 18。其中一部分是治理、隐私以及对 GDPR、CCPA 等法规的遵从;我们会在“数据系统、法律与社会”和“立法与行业自律”中讨论。
此外,分析数据的提供形式也越来越多样:不仅有文件和关系表,也有事件流(见第 12 章)。基于文件的分析通常通过周期性重跑(例如每天一次)来响应数据变化,而流处理能够让分析系统在秒级响应事件。对于时效性要求高的场景,这种方式很有价值,例如识别并阻断潜在的欺诈或滥用行为。
在某些场景中,分析系统的输出还会回流到事务型系统(这一过程有时称为 反向 ETL 19)。例如,在分析系统里训练出的机器学习模型会部署到生产环境,为终端用户生成“买了 X 的人也买了 Y”这类推荐。此类分析系统的投产结果也称为 数据产品 20。机器学习模型可借助 TFX、Kubeflow、MLflow 等专用工具部署到事务型系统。
记录系统与派生数据
与事务型系统和分析型系统的区分相关,本书还区分 记录系统 与 派生数据系统。这组术语有助于你理清数据在系统中的流向:
- 权威记录系统
- 记录系统,也称 真相来源(权威数据源),保存某类数据的权威(canonical)版本。新数据进入系统时(例如用户输入)首先写入这里。每个事实只表示一次(这种表示通常是 规范化 的;见“规范化、反规范化与连接”)。如果其他系统与记录系统不一致,则按定义以记录系统为准。
- 派生数据系统
- 派生系统中的数据,是对其他系统中已有数据进行转换或处理后的结果。如果派生数据丢失,可以从原始数据源重新构建。经典例子是缓存:命中时由缓存返回,未命中时回退到底层数据库。反规范化值、索引、物化视图、变换后的数据表示,以及在数据集上训练出的模型,都属于这一类。
从技术上说,派生数据是 冗余 的,因为它复制了已有信息。但它往往是读查询高性能的关键。你可以从同一个源数据派生出多个数据集,以不同“视角”观察同一份事实。
分析系统通常属于派生数据系统,因为它消费的是别处产生的数据。事务型服务往往同时包含记录系统和派生数据系统:前者是数据首先写入的主数据库,后者则是用于加速常见读取操作的索引与缓存,尤其针对记录系统难以高效回答的查询。
大多数数据库、存储引擎和查询语言本身并不天然属于“记录系统”或“派生系统”。数据库只是工具,关键在于你如何使用它。两者的区别不在工具本身,而在应用中的职责划分。只要明确“哪些数据由哪些数据派生而来”,原本混乱的系统架构就会清晰很多。
当一个系统的数据由另一个系统的数据派生而来时,你需要在记录系统原始数据变化时同步更新派生数据。不幸的是,很多数据库默认假设应用只依赖单一数据库,并不擅长在多系统之间传播这类更新。在“数据集成”中,我们会讨论如何组合多个数据系统,实现单一系统难以独立完成的能力。
至此,我们结束了对分析与事务处理的比较。下一节将讨论另一组常被反复争论的权衡。
云服务与自托管
对于组织需要做的任何事情,首要问题之一是:应该在内部完成,还是应该外包?应该自建还是购买?
归根结底,这是一个关于业务优先级的问题。公认的管理智慧是,作为组织核心竞争力或竞争优势的事物应该在内部完成,而非核心、例行或常见的事物应该留给供应商 21。 举一个极端的例子,大多数公司不会自己发电(除非他们是能源公司,而且不考虑紧急备用电源),因为从电网购买电力更便宜。
对于软件,需要做出的两个重要决定是谁构建软件和谁部署它。有一系列可能性,每个决定都在不同程度上外包,如图 1-2 所示。 一个极端是你自己编写并在内部运行的定制软件;另一个极端是广泛使用的云服务或软件即服务(SaaS)产品,由外部供应商实施和运营,你只能通过 Web 界面或 API 访问。

中间地带是你 自托管 的现成软件(开源或商业),即自己部署——例如,如果你下载 MySQL 并将其安装在你控制的服务器上。 这可能在你自己的硬件上(通常称为 本地部署,即使服务器实际上在租用的数据中心机架中而不是字面上在你自己的场所) ,或者在云中的虚拟机上(基础设施即服务 或 IaaS)。沿着这个范围还有更多的点,例如,采用开源软件并运行其修改版本。
与这个范围分开的还有 如何 部署服务的问题,无论是在云中还是在本地——例如,是否使用 Kubernetes 等编排框架。 然而,部署工具的选择超出了本书的范围,因为其他因素对数据系统的架构有更大的影响。
云服务的利弊
使用云服务而不是自己运行对应的软件,本质上是将该软件的运维外包给云提供商。 使用云服务有充分的支持和反对理由。云提供商声称,使用他们的服务可以节省你的时间和金钱,并相比自建基础设施让你更敏捷。
云服务实际上是否比自托管更便宜、更容易,很大程度上取决于你的技能和系统的工作负载。 如果你已经有设置和运维所需系统的经验,并且你的负载相当可预测(即,你需要的机器数量不会剧烈波动), 那么购买自己的机器并自己在上面运行软件通常更便宜 22 23。
另一方面,如果你需要一个你还不知道如何部署和运维的系统,那么采用云服务通常比学习自己管理系统更容易、更快。 如果你必须专门雇用和培训员工来维护和运营系统,那可能会变得非常昂贵。 使用云时你仍然需要一个运维团队(参见“云时代的运维”),但外包基本的系统管理可以让你的团队专注于更高层次的问题。
当你将系统的运维外包给专门运维该服务的公司时,可能会带来更好的服务,因为供应商在向许多客户提供服务中获得了专业运维知识。 另一方面,如果你自己运维服务,你可以配置和调整它,以专门针对你特定的工作负载进行优化,而云服务不太可能愿意替你进行此类定制。
如果你的系统负载随时间变化很大,云服务特别有价值。如果你配置机器以能够处理峰值负载,但这些计算资源大部分时间都处于空闲状态,系统就变得不太具有成本效益。 在这种情况下,云服务的优势在于它们可以更容易地根据需求变化向上或向下扩展你的计算资源。
例如,分析系统通常具有极其可变的负载:快速运行大型分析查询需要并行使用大量计算资源,但一旦查询完成,这些资源就会处于空闲状态,直到用户进行下一个查询。 预定义的查询(例如,每日报告)可以排队和调度以平滑负载,但对于交互式查询,你越希望它们完成得快,工作负载就变得越可变。 如果你的数据集如此之大,以至于快速查询需要大量的计算资源,使用云可以节省资金,因为你可以将未使用的资源返回给供应商,而不是让它们闲置。对于较小的数据集,这种差异不太显著。
云服务的最大缺点是你无法控制它:
- 如果它缺少你需要的功能,你所能做的就是礼貌地询问供应商是否会添加它;你通常无法自己实现它。
- 如果服务宕机,你所能做的就是等它恢复。
- 如果你以触发错误或导致性能问题的方式使用服务,你将很难诊断问题。对于你自己运行的软件,你可以从操作系统获取性能指标和调试信息来帮助你理解其行为,你可以查看服务器日志,但对于供应商托管的服务,你通常无法访问这些内部信息。
- 此外,如果服务关闭或变得无法接受的昂贵,或者如果供应商决定以你不喜欢的方式更改他们的产品,你就受制于他们 —— 继续运行旧版本的软件通常不是一个可行选项,所以你将被迫迁移到替代服务 24。 如果有暴露兼容 API 的替代服务,这种风险会得到缓解,但对于许多云服务,没有标准 API,这增加了切换成本,使供应商锁定成为一个问题。
- 云供应商需要被信任以保持数据安全,这可能会使遵守隐私和安全法规的过程复杂化。
尽管有所有这些风险,组织在云服务之上构建新应用程序或采用混合方法(在系统的某些部分使用云服务)变得越来越流行。然而,云服务不会取代所有内部数据系统:许多较旧的系统早于云,对于任何具有现有云服务无法满足的专业要求的服务,内部系统仍然是必要的。例如,对延迟非常敏感的应用程序(如高频交易)需要对硬件的完全控制。
云原生系统架构
除了具有不同的经济模型(订阅服务而不是购买硬件和许可软件在其上运行)之外,云的兴起也对数据系统在技术层面的实现产生了深远的影响。 术语 云原生 用于描述旨在利用云服务的架构。
原则上,几乎任何可自托管的软件都可以做成云服务;事实上,许多主流数据系统都已有托管版本。 不过,从零设计为云原生的系统已经展示出若干优势:同等硬件下性能更好、故障恢复更快、能更快按负载扩缩计算资源,并支持更大数据集 25 26 27。表 1-2 给出两类系统的一些示例。
表 1-2. 自托管与云原生数据库系统示例
| 类别 | 自托管系统 | 云原生系统 |
|---|---|---|
| 事务型/OLTP | MySQL、PostgreSQL、MongoDB | AWS Aurora 25、Azure SQL DB Hyperscale 26、Google Cloud Spanner |
| 分析型/OLAP | Teradata、ClickHouse、Spark | Snowflake 27、Google BigQuery、Azure Synapse Analytics |
云服务的分层
许多自托管数据系统的系统要求非常简单:它们在传统操作系统(如 Linux 或 Windows)上运行,将数据存储为文件系统上的文件,并通过 TCP/IP 等标准网络协议进行通信。 少数系统依赖于特殊硬件,如 GPU(用于机器学习)或 RDMA 网络接口,但总的来说,自托管软件倾向于使用非常通用的计算资源:CPU、RAM、文件系统和 IP 网络。
在云中,这种类型的软件可以在基础设施即服务(IaaS)环境中运行,使用一个或多个虚拟机(或 实例),分配一定的 CPU、内存、磁盘和网络带宽。 与物理机器相比,云实例可以更快地配置,并且有更多种类的大小,但除此之外,它们与传统计算机类似:你可以在上面运行任何你喜欢的软件,但你负责自己管理它。
相比之下,云原生服务的关键思想是不仅使用由操作系统管理的计算资源,还基于较低级别的云服务构建更高级别的服务。例如:
- 使用 对象存储 服务(如 Amazon S3、Azure Blob Storage 和 Cloudflare R2)存储大文件。它们提供比典型文件系统更有限的 API(基本文件读写),但它们的优势在于隐藏了底层物理机器:服务自动将数据分布在许多机器上,因此你不必担心任何一台机器上的磁盘空间用完。即使某些机器或其磁盘完全故障,也不会丢失数据。
- 在对象存储和其他云服务之上建立更多的服务:例如,Snowflake 是一个基于云的分析数据库(数据仓库),依赖于 S3 进行数据存储 27,而一些其他服务反过来建立在 Snowflake 之上。
与计算中的抽象一样,没有一个正确的答案告诉你应该使用什么。作为一般规则,更高级别的抽象往往更面向特定的用例。如果你的需求与为其设计更高级别系统的情况相匹配,使用现有的高级别系统可能会比自己从较低级别系统构建更轻松,且更能满足您的需求。另一方面,如果没有满足你需求的高级系统,那么从较低级别的组件自己构建它是唯一的选择。
存储与计算的分离
在传统计算中,磁盘存储被认为是持久的(我们假设一旦某些东西被写入磁盘,它就不会丢失)。为了容忍单个硬盘的故障,通常使用 RAID(独立磁盘冗余阵列)在连接到同一台机器的几个磁盘上维护数据副本。RAID 可以在硬件中执行,也可以由操作系统在软件中执行,它对访问文件系统的应用程序是透明的。
在云中,计算实例(虚拟机)也可能有本地磁盘连接,但云原生系统通常将这些磁盘更多地视为临时缓存,而不是长期存储。这是因为如果关联的实例出现故障,或者为了适应负载变化而将实例替换为更大或更小的实例(在不同的物理机器上),本地磁盘就会变得不可访问。
作为本地磁盘的替代方案,云服务还提供可以从一个实例分离并附加到另一个实例的虚拟磁盘存储(Amazon EBS、Azure 托管磁盘和 Google Cloud 中的持久磁盘)。这种虚拟磁盘实际上不是物理磁盘,而是由一组单独的机器提供的云服务,它模拟磁盘的行为(块设备,其中每个块通常为 4 KiB 大小)。这项技术使得在云中运行传统的基于磁盘的软件成为可能,但块设备仿真所引入的开销在一开始就为云设计的系统中是可以避免的 25。它还使应用程序对网络故障非常敏感,因为虚拟块设备上的每个 I/O 实际上都是网络调用 28。
为了解决这个问题,云原生服务通常避免使用虚拟磁盘,而是建立在针对特定工作负载优化的专用存储服务之上。对象存储服务(如 S3)设计用于长期存储相当大的文件,大小从数百 KB 到几 GB 不等。数据库中存储的单个行或值通常比这小得多;因此,云数据库通常在单独的服务中管理较小的值,并将较大的数据块(包含许多单个值)存储在对象存储中 26 29。我们将在第 4 章中看到这样做的方法。
在传统的系统架构中,同一台计算机负责存储(磁盘)和计算(CPU 和 RAM),但在云原生系统中,这两个职责已经在某种程度上分离或 解耦 9 27 30 31:例如,S3 只存储文件,如果你想分析该数据,你必须在 S3 之外的某个地方运行分析代码。这意味着通过网络传输数据,我们将在“分布式与单节点系统”中进一步讨论。
此外,云原生系统通常是 多租户 的,这意味着不是每个客户都有一台单独的机器,而是来自几个不同客户的数据和计算由同一服务在同一共享硬件上处理 32。
多租户可以实现更好的硬件利用率、更容易的可伸缩性和云提供商更容易的管理,但它也需要仔细的工程设计,以确保一个客户的活动不会影响其他客户的系统的性能或安全性 33。
云时代的运维
传统上,管理组织服务器端数据基础设施的人员被称为 数据库管理员(DBA)或 系统管理员(sysadmins)。最近,许多组织已经尝试将软件开发和运维的角色整合到团队中,共同负责后端服务和数据基础设施;DevOps 理念引导了这一趋势。站点可靠性工程师(SRE)是 Google 对这个想法的实现 34。
运维的作用是确保服务可靠地交付给用户(包括配置基础设施和部署应用程序),并确保稳定的生产环境(包括监控和诊断可能影响可靠性的任何问题)。对于自托管系统,运维传统上涉及大量在单个机器级别的工作,例如容量规划(例如,监控可用磁盘空间并在空间用完之前添加更多磁盘)、配置新机器、将服务从一台机器移动到另一台机器,以及安装操作系统补丁。
许多云服务提供了 API 来隐藏实际实现服务的单个机器。例如,云存储用 计量计费 替换固定大小的磁盘,你可以存储数据而无需提前规划容量需求,然后根据实际使用的空间收费。此外,即使在单个机器发生故障时,许多云服务仍能保持高可用性(参见“可靠性与容错”)。
从单个机器到服务的重点转移伴随着运维角色的变化。提供可靠服务的高级目标保持不变,但流程和工具已经发展。DevOps/SRE 理念更加强调:
- 自动化——优先考虑可重复的流程而不是手动的一次性工作,
- 优先考虑短暂的虚拟机和服务而不是长期运行的服务器,
- 启用频繁的应用程序更新,
- 从事故中学习,以及
- 保留组织关于系统的知识,即使组织里的人员在不断流动 35。
随着云服务的兴起,角色出现了分叉:基础设施公司的运维团队专门研究向大量客户提供可靠服务的细节,而服务的客户在基础设施上花费尽可能少的时间和精力 36。
云服务的客户仍然需要运维,但他们专注于不同的方面,例如为给定任务选择最合适的服务、将不同服务相互集成,以及从一个服务迁移到另一个服务。即使计量计费消除了传统意义上的容量规划需求,了解你为哪个目的使用哪些资源仍然很重要,这样你就不会在不需要的云资源上浪费金钱:容量规划变成了财务规划,性能优化变成了成本优化 37。
此外,云服务确实有资源限制或 配额(例如你可以同时运行的最大进程数),你需要在遇到它们之前了解并规划这些 38。
采用云服务可能比运行自己的基础设施更容易、更快,尽管学习如何使用它也有成本,也许还要解决其限制。随着越来越多的供应商提供针对不同用例的更广泛的云服务,不同服务之间的集成成为一个特别的挑战 39 40。
ETL(参见“数据仓库”)只是故事的一部分;面向事务处理的云服务之间也需要相互集成。目前,缺乏能促进这类集成的标准,因此往往仍要投入大量手工工作。
无法完全外包给云服务的其他运维方面包括维护应用程序及其使用的库的安全性、管理你自己的服务之间的交互、监控服务的负载,以及追踪问题的原因,例如性能下降或中断。虽然云正在改变运维的角色,但对运维的需求比以往任何时候都大。
分布式与单节点系统
涉及多台机器通过网络通信的系统称为 分布式系统。参与分布式系统的每个进程称为 节点。你希望采用分布式系统的原因可能有多种:
- 固有的分布式系统
- 如果应用程序涉及两个或多个交互用户,每个用户使用自己的设备,那么系统不可避免地是分布式的:设备之间的通信必须通过网络进行。
- 云服务之间的请求
- 如果数据存储在一个服务中但在另一个服务中处理,则必须通过网络从一个服务传输到另一个服务。
- 容错/高可用性
- 如果你的应用程序需要在一台机器(或几台机器、网络或整个数据中心)发生故障时继续工作,你可以使用多台机器为你提供冗余。当一台故障时,另一台可以接管。参见“可靠性与容错”和第 6 章关于复制的内容。
- 可伸缩性
- 如果你的数据量或计算需求增长超过单台机器的处理能力,你可以潜在地将负载分散到多台机器上。参见“可伸缩性”。
- 延迟
- 如果你在世界各地都有用户,你可能希望在全球各个地区都有服务器,以便每个用户都可以从地理位置接近他们的服务器获得服务。这避免了用户必须等待网络数据包绕地球半圈才能回答他们的请求。参见“描述性能”。
- 弹性
- 如果你的应用程序在某些时候很忙,在其他时候很空闲,云部署可以根据需求向上或向下伸缩,因此你只需为实际使用的资源付费。这在单台机器上更困难,它需要按处理最大负载的情况进行配置,即使在几乎不使用的时候也是如此。
- 使用专用硬件
- 系统的不同部分可以利用不同类型的硬件来匹配其工作负载。例如,对象存储可能使用具有许多磁盘但很少 CPU 的机器,而数据分析系统可能使用具有大量 CPU 和内存但没有磁盘的机器,机器学习系统可能使用具有 GPU 的机器(GPU 在训练深度神经网络和其他机器学习任务方面比 CPU 效率高得多)。
- 法律合规
- 一些国家有数据驻留法律,要求其管辖范围内的人员数据必须在该国地理范围内存储和处理 41。这些规则的范围各不相同——例如,在某些情况下,它仅适用于医疗或金融数据,而其他情况则更广泛。因此,在几个这样的管辖区域中拥有用户的服务不得不将他们的数据分布在几个位置的服务器上。
- 可持续性
- 如果你能灵活把控作业运行的地点和时间,你可能能够在可再生电力充足的时间和地点运行它们,并避免在电网紧张时运行它们。这可以减少你的碳排放,并允许你利用到廉价的电力 42 43。
这些原因既适用于你自己编写的服务(应用程序代码),也适用于由现成软件(如数据库)组成的服务。
分布式系统的问题
分布式系统也有缺点。通过网络进行的每个请求和 API 调用都需要处理失败的可能性:网络可能中断,或者服务可能过载或崩溃,因此任何请求都可能超时而没有收到响应。在这种情况下,我们不知道服务是否收到了请求,简单地重试它可能不安全。我们将在第 9 章中详细讨论这些问题。
尽管数据中心网络很快,但调用另一个服务仍然比在同一进程中调用函数慢得多 44。
在处理大量数据时,与其将数据从其存储处传输到处理它的单独机器,将计算带到已经拥有数据的机器上可能更快 45。
更多的节点并不总是更快:在某些情况下,一个简单的单线程程序在单台计算机上运行的性能可以比在具有 100 多个 CPU 核心的集群上更好 46。
对分布式系统进行故障排除通常很困难:如果系统响应缓慢,你如何找出问题所在?可观测性 47 48 技术可以用来对分布式系统中的问题进行诊断,这涉及到系统执行数据的收集,并提供查询方式来支持对高层级的指标或单个的事件的分析。追踪 工具(如 OpenTelemetry、Zipkin 和 Jaeger)允许你跟踪哪个客户端为哪个操作调用了哪个服务器,以及每次调用花费了多长时间 49。
数据库提供了各种机制来确保数据一致性,正如我们将在第 6 章和第 8 章中看到的。然而,当每个服务都有自己的数据库时,维护这些不同服务之间的数据一致性就成了应用程序的问题。分布式事务(我们在第 8 章中探讨)是确保一致性的一种可能技术,但它们在微服务上下文中很少使用,因为它们违背了使服务彼此独立的目标,而且许多数据库不支持它们 50。
出于所有这些原因,如果你可以在单台机器上做某件事情,与搭建分布式系统相比通常要简单得多,成本也更低 23 46 51。CPU、内存和磁盘已经变得更大、更快、更可靠。当与 DuckDB、SQLite 和 KùzuDB 等单节点数据库结合使用时,许多工作负载现在可以在单个节点上运行。我们将在第 4 章中进一步探讨这个主题。
微服务与无服务器
在多台机器上分布系统的最常见方式是将它们分为客户端和服务器,并让客户端向服务器发出请求。最常见的是使用 HTTP 进行此通信,正如我们将在“流经服务的数据流:REST 和 RPC”中讨论的。同一进程可能既是服务器(处理传入请求)又是客户端(向其他服务发出出站请求)。
这种构建应用程序的方式传统上被称为 面向服务的体系结构(SOA);最近,这个想法已经被细化为 微服务 架构 52 53。在这种架构中,服务有一个明确定义的目的(例如,对于 S3 来说,这个目的是文件存储);每个服务公开一个可以由客户端通过网络调用的 API,每个服务有一个负责其维护的团队。因此,复杂的应用程序可以分解为多个交互服务,每个服务由单独的团队管理。
将复杂的软件分解为多个服务有几个优点:每个服务可以独立更新,减少团队之间的协调工作;每个服务可以分配它需要的硬件资源;通过将实现细节隐藏在 API 后面,服务所有者可以自由地更改实现而不影响客户端。在数据存储方面,每个服务通常有自己的数据库,而不在服务之间共享数据库:共享数据库实际上会使整个数据库结构成为服务 API 的一部分,然后该结构将很难更改。共享数据库还可能导致一个服务的查询对其他服务的性能产生负面影响。
另一方面,拥有许多服务本身可能会带来复杂性:每个服务都需要用于部署新版本、调整分配的硬件资源以匹配负载、收集日志、监控服务健康状况以及在出现问题时向值班工程师发出警报的基础设施。编排 框架(如 Kubernetes)已成为部署服务的流行方式,因为它们为这种基础设施提供了基础。在开发期间测试服务可能很复杂,因为你还需要运行它所依赖的所有其他服务。
微服务 API 的演进可能具有挑战性。调用 API 的客户端期望 API 具有某些字段。开发人员可能希望根据业务需求的变化向 API 添加或删除字段,但这样做可能会导致客户端失败。更糟糕的是,这种失败通常直到开发周期的后期才被发现,当更新的服务 API 部署到预生产或生产环境时。API 描述标准(如 OpenAPI 和 gRPC)有助于管理客户端和服务器 API 之间的关系;我们将在第 5 章中进一步讨论这些。
微服务主要是人员问题的技术解决方案:允许不同的团队独立取得进展,而无需相互协调。这在大公司中很有价值,但在没有很多团队的小公司中,使用微服务可能是不必要的开销,最好以最简单的方式实现应用程序 52。
无服务器(Serverless),或 函数即服务(FaaS),是另一种部署方式:基础设施管理进一步外包给云厂商 33。使用虚拟机时,你需要显式决定何时启动、何时关闭实例;而在无服务器模型中,云厂商会根据进入服务的请求自动分配和回收计算资源 54。这种部署方式把更多运维负担转移给云厂商,并支持按使用量计费,而不是按实例计费。为实现这些优势,许多无服务器平台会限制函数执行时长、限制运行时环境,并在函数首次调用时出现较慢冷启动。术语“无服务器”本身也容易误导:每次函数执行依然运行在某台服务器上,只是后续执行未必在同一台机器上。此外,BigQuery 及多种 Kafka 产品也采用“Serverless”术语,强调其服务可自动扩缩容且按使用量计费。
就像云存储以计量计费取代了传统容量规划(预先决定买多少磁盘)一样,无服务器模式把同样的计费逻辑带到了代码执行层:你只为代码实际运行的时间付费,而不必预先准备固定资源。
云计算与超级计算
云计算不是构建大规模计算系统的唯一方式;另一种选择是 高性能计算(HPC),也称为 超级计算。尽管有重叠,但与云计算和企业数据中心系统相比,HPC 通常有不同的设计考量并使用不同的技术。其中一些差异是:
- 超级计算机通常用于计算密集型科学计算任务,例如天气预报、气候建模、分子动力学(模拟原子和分子的运动)、复杂的优化问题和求解偏微分方程。另一方面,云计算往往用于在线服务、业务数据系统和需要以高可用性为用户请求提供服务的类似系统。
- 超级计算机通常运行大型批处理作业,定期将其计算状态检查点保存到磁盘。如果节点发生故障,常见的解决方案是简单地停止整个集群工作负载,修复故障节点,然后从最后一个检查点重新启动计算 55 56。对于云服务,通常不希望停止整个集群,因为服务需要以最小的中断持续为用户提供服务。
- 超级计算机节点通常通过共享内存和远程直接内存访问(RDMA)进行通信,这支持高带宽和低延迟,但假设系统用户之间有高度的信任 57。在云计算中,网络和机器通常由相互不信任的组织共享,需要更强的安全机制,如资源隔离(例如虚拟机)、加密和身份验证。
- 云数据中心网络通常基于 IP 和以太网,以 Clos 拓扑排列以提供高对分带宽——这是网络整体性能的常用度量 55 58。超级计算机通常使用专门的网络拓扑,例如多维网格和环面 59,这能让具有已知通信模式的 HPC 工作负载产生更好的性能。
- 云计算允许节点分布在多个地理区域,而超级计算机通常假设它们的所有节点都靠近在一起。
大规模分析系统有时与超级计算共享一些特征,如果你在这个领域工作,了解这些技术可能是值得的。然而,本书主要关注需要持续可用的服务,如“可靠性与容错”中所讨论的。
数据系统、法律与社会
到目前为止,你已经在本章中看到,数据系统的架构不仅受到技术目标和要求的影响,还受到它们所支持的组织的人力需求的影响。越来越多的数据系统工程师认识到,仅服务于自己企业的需求是不够的:我们还对整个社会负有责任。
一个特别的关注点是存储有关人员及其行为数据的系统。自 2018 年以来,通用数据保护条例(GDPR)赋予了许多欧洲国家居民对其个人数据更大的控制权和法律权利,类似的隐私法规已在世界各地的各个国家和州采用,例如加州消费者隐私法(CCPA)。关于 AI 的法规,例如 欧盟 AI 法案,对个人数据的使用方式施加了进一步的限制。
此外,即使在不直接受法规约束的领域,人们也越来越认识到计算机系统对人和社会的影响。社交媒体改变了个人消费新闻的方式,这影响了他们的政治观点,因此可能影响选举结果。自动化系统越来越多地做出对个人产生深远影响的决策,例如决定谁应该获得贷款或保险覆盖,谁应该被邀请参加工作面试,或者谁应该被怀疑犯罪 60。
每个从事此类系统工作的人都有责任考虑道德影响并确保他们遵守相关法律。没有必要让每个人都成为法律和道德专家,但对法律和道德原则的基本认识与分布式系统中的一些基础知识同样重要。
法律考虑正在影响数据系统设计的基础 61。例如,GDPR 授予个人在请求时删除其数据的权利(有时称为 被遗忘权)。然而,正如我们将在本书中看到的,许多数据系统依赖不可变构造(如仅追加日志)作为其设计的一部分;我们如何确保删除应该不可变的文件中间的某些数据?我们如何处理已被纳入派生数据集(参见“记录系统与派生数据”)的数据删除,例如机器学习模型的训练数据?回答这些问题会带来新的工程挑战。
目前,我们对于哪些特定技术或系统架构应被视为“符合 GDPR”没有明确的指导方针。法规故意不强制要求特定技术,因为随着技术的进步,这些技术可能会迅速变化。相反,法律文本规定了需要解释的高层级原则。这意味着如何遵守隐私法规的问题没有简单的答案,但我们将通过这个视角来看待本书中的一些技术。
一般来说,我们存储数据是因为我们认为其价值大于存储它的成本。然而,值得记住的是,存储成本不仅仅是你为 Amazon S3 或其他服务支付的账单:成本效益计算还应该考虑到如果数据被泄露或被对手入侵的责任和声誉损害风险,以及如果数据的存储和处理被发现不符合法律的法律成本和罚款风险 51。
政府或警察部队也可能迫使公司交出数据。当存在数据可能暴露犯罪行为的风险时(例如,在几个中东和非洲国家的同性恋,或在几个美国州寻求堕胎),存储该数据会为用户创造真正的安全风险。例如,去堕胎诊所的行程很容易被位置数据泄露,甚至可能通过用户 IP 地址随时间的日志(表示大致位置)泄露。
一旦考虑到所有风险,可能合理地决定某些数据根本不值得存储,因此应该删除。这个 数据最小化 原则(有时以德语术语 Datensparsamkeit 为人所知)与“大数据”哲学相反,后者是投机性地存储大量数据,以防将来有用 62。但它符合 GDPR,该法规要求个人数据只能为指定的、明确的目的收集,这些数据以后不得用于任何其他目的,并且数据不得保留超过收集目的所需的时间 63。
企业也注意到了隐私和安全问题。信用卡公司要求处理支付的企业遵守严格的支付卡行业(PCI)标准。处理商需要经常接受独立审计师的评估,以验证持续的合规性。软件供应商也受到了更多的审查。现在许多买家要求他们的供应商遵守服务组织控制(SOC)类型 2 标准。与 PCI 合规性一样,供应商需要接受第三方审计以验证遵守情况。
总的来说,关键在于平衡业务目标与被收集、被处理数据的人们的权益。这个主题还有很多内容;在第 14 章中,我们会进一步讨论伦理与法律合规,以及偏见与歧视等问题。
总结
本章的主线是理解“权衡”。对许多问题而言,并不存在唯一正确答案,而是有多种路径,各有利弊。我们讨论了影响数据系统架构的几个关键选择,并引入了后续章节会反复使用的术语。
我们首先区分了事务型(事务处理,OLTP)和分析型(OLAP)系统。它们不仅面对不同访问模式与数据类型,也服务于不同人群。我们还看到数据仓库与数据湖这两类体系,它们通过 ETL 接收来自事务型系统的数据。在第 4 章中,我们会看到由于查询类型不同,事务型与分析型系统常常采用截然不同的内部数据布局。
随后,我们把相对较新的云服务模式与长期主导数据系统架构的自托管范式做了比较。哪种方式更具成本效益高度依赖具体情境,但不可否认,云原生架构正在深刻改变数据系统的构建方式,例如存储与计算的分离。
云系统天然是分布式系统,我们也简要讨论了它与单机方案之间的权衡。有些场景无法避免分布式,但如果单机可行,不必急于把系统分布式化。在第 9 章中,我们会更深入地讨论分布式系统的挑战。
最后,数据系统架构不仅由企业自身需求决定,也受保护数据主体权利的隐私法规所塑造,而这一点常被工程实践忽略。如何把法律要求转化为技术实现,目前仍无标准答案;但在阅读本书后续内容时,始终带着这个问题会很重要。
参考文献
Richard T. Kouzes, Gordon A. Anderson, Stephen T. Elbert, Ian Gorton, and Deborah K. Gracio. The Changing Paradigm of Data-Intensive Computing. IEEE Computer, volume 42, issue 1, January 2009. doi:10.1109/MC.2009.26 ↩︎
Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan. Local-first software: you own your data, in spite of the cloud. At 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!), October 2019. doi:10.1145/3359591.3359737 ↩︎
Joe Reis and Matt Housley. Fundamentals of Data Engineering. O’Reilly Media, 2022. ISBN: 9781098108304 ↩︎
Rui Pedro Machado and Helder Russa. Analytics Engineering with SQL and dbt. O’Reilly Media, 2023. ISBN: 9781098142384 ↩︎
Edgar F. Codd, S. B. Codd, and C. T. Salley. Providing OLAP to User-Analysts: An IT Mandate. E. F. Codd Associates, 1993. Archived at perma.cc/RKX8-2GEE ↩︎
Chinmay Soman and Neha Pawar. Comparing Three Real-Time OLAP Databases: Apache Pinot, Apache Druid, and ClickHouse. startree.ai, April 2023. Archived at perma.cc/8BZP-VWPA ↩︎
Surajit Chaudhuri and Umeshwar Dayal. An Overview of Data Warehousing and OLAP Technology. ACM SIGMOD Record, volume 26, issue 1, pages 65–74, March 1997. doi:10.1145/248603.248616 ↩︎
Fatma Özcan, Yuanyuan Tian, and Pinar Tözün. Hybrid Transactional/Analytical Processing: A Survey. At ACM International Conference on Management of Data (SIGMOD), May 2017. doi:10.1145/3035918.3054784 ↩︎
Adam Prout, Szu-Po Wang, Joseph Victor, Zhou Sun, Yongzhu Li, Jack Chen, Evan Bergeron, Eric Hanson, Robert Walzer, Rodrigo Gomes, and Nikita Shamgunov. Cloud-Native Transactions and Analytics in SingleStore. At International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526055 ↩︎ ↩︎
Chao Zhang, Guoliang Li, Jintao Zhang, Xinning Zhang, and Jianhua Feng. HTAP Databases: A Survey. IEEE Transactions on Knowledge and Data Engineering, April 2024. doi:10.1109/TKDE.2024.3389693 ↩︎
Michael Stonebraker and Uğur Çetintemel. ‘One Size Fits All’: An Idea Whose Time Has Come and Gone. At 21st International Conference on Data Engineering (ICDE), April 2005. doi:10.1109/ICDE.2005.1 ↩︎
Jeffrey Cohen, Brian Dolan, Mark Dunlap, Joseph M. Hellerstein, and Caleb Welton. MAD Skills: New Analysis Practices for Big Data. Proceedings of the VLDB Endowment, volume 2, issue 2, pages 1481–1492, August 2009. doi:10.14778/1687553.1687576 ↩︎
Dan Olteanu. The Relational Data Borg is Learning. Proceedings of the VLDB Endowment, volume 13, issue 12, August 2020. doi:10.14778/3415478.3415572 ↩︎
Matt Bornstein, Martin Casado, and Jennifer Li. Emerging Architectures for Modern Data Infrastructure: 2020. future.a16z.com, October 2020. Archived at perma.cc/LF8W-KDCC ↩︎
Martin Fowler. DataLake. martinfowler.com, February 2015. Archived at perma.cc/4WKN-CZUK ↩︎
Bobby Johnson and Joseph Adler. The Sushi Principle: Raw Data Is Better. At Strata+Hadoop World, February 2015. ↩︎
Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. At 11th Annual Conference on Innovative Data Systems Research (CIDR), January 2021. ↩︎
DataKitchen, Inc. The DataOps Manifesto. dataopsmanifesto.org, 2017. Archived at perma.cc/3F5N-FUQ4 ↩︎
Tejas Manohar. What is Reverse ETL: A Definition & Why It’s Taking Off. hightouch.io, November 2021. Archived at perma.cc/A7TN-GLYJ ↩︎
Simon O’Regan. Designing Data Products. towardsdatascience.com, August 2018. Archived at perma.cc/HU67-3RV8 ↩︎
Camille Fournier. Why is it so hard to decide to buy? skamille.medium.com, July 2021. Archived at perma.cc/6VSG-HQ5X ↩︎
David Heinemeier Hansson. Why we’re leaving the cloud. world.hey.com, October 2022. Archived at perma.cc/82E6-UJ65 ↩︎
Nima Badizadegan. Use One Big Server. specbranch.com, August 2022. Archived at perma.cc/M8NB-95UK ↩︎ ↩︎
Steve Yegge. Dear Google Cloud: Your Deprecation Policy is Killing You. steve-yegge.medium.com, August 2020. Archived at perma.cc/KQP9-SPGU ↩︎
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. At ACM International Conference on Management of Data (SIGMOD), pages 1041–1052, May 2017. doi:10.1145/3035918.3056101 ↩︎ ↩︎ ↩︎
Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. Socrates: The New SQL Server in the Cloud. At ACM International Conference on Management of Data (SIGMOD), pages 1743–1756, June 2019. doi:10.1145/3299869.3314047 ↩︎ ↩︎ ↩︎
Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Motivala, and Thierry Cruanes. Building An Elastic Query Engine on Disaggregated Storage. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎ ↩︎ ↩︎ ↩︎
Nick Van Wiggeren. The Real Failure Rate of EBS. planetscale.com, March 2025. Archived at perma.cc/43CR-SAH5 ↩︎
Colin Breck. Predicting the Future of Distributed Systems. blog.colinbreck.com, August 2024. Archived at perma.cc/K5FC-4XX2 ↩︎
Gwen Shapira. Compute-Storage Separation Explained. thenile.dev, January 2023. Archived at perma.cc/QCV3-XJNZ ↩︎
Ravi Murthy and Gurmeet Goindi. AlloyDB for PostgreSQL under the hood: Intelligent, database-aware storage. cloud.google.com, May 2022. Archived at archive.org ↩︎
Jack Vanlightly. The Architecture of Serverless Data Systems. jack-vanlightly.com, November 2023. Archived at perma.cc/UDV4-TNJ5 ↩︎
Eric Jonas, Johann Schleier-Smith, Vikram Sreekanti, Chia-Che Tsai, Anurag Khandelwal, Qifan Pu, Vaishaal Shankar, Joao Carreira, Karl Krauth, Neeraja Yadwadkar, Joseph E. Gonzalez, Raluca Ada Popa, Ion Stoica, David A. Patterson. Cloud Programming Simplified: A Berkeley View on Serverless Computing. arxiv.org, February 2019. ↩︎ ↩︎
Betsy Beyer, Jennifer Petoff, Chris Jones, and Niall Richard Murphy. Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media, 2016. ISBN: 9781491929124 ↩︎
Thomas Limoncelli. The Time I Stole $10,000 from Bell Labs. ACM Queue, volume 18, issue 5, November 2020. doi:10.1145/3434571.3434773 ↩︎
Charity Majors. The Future of Ops Jobs. acloudguru.com, August 2020. Archived at perma.cc/GRU2-CZG3 ↩︎
Boris Cherkasky. (Over)Pay As You Go for Your Datastore. medium.com, September 2021. Archived at perma.cc/Q8TV-2AM2 ↩︎
Shlomi Kushchi. Serverless Doesn’t Mean DevOpsLess or NoOps. thenewstack.io, February 2023. Archived at perma.cc/3NJR-AYYU ↩︎
Erik Bernhardsson. Storm in the stratosphere: how the cloud will be reshuffled. erikbern.com, November 2021. Archived at perma.cc/SYB2-99P3 ↩︎
Benn Stancil. The data OS. benn.substack.com, September 2021. Archived at perma.cc/WQ43-FHS6 ↩︎
Maria Korolov. Data residency laws pushing companies toward residency as a service. csoonline.com, January 2022. Archived at perma.cc/CHE4-XZZ2 ↩︎
Severin Borenstein. Can Data Centers Flex Their Power Demand? energyathaas.wordpress.com, April 2025. Archived at https://perma.cc/MUD3-A6FF ↩︎
Bilge Acun, Benjamin Lee, Fiodar Kazhamiaka, Aditya Sundarrajan, Kiwan Maeng, Manoj Chakkaravarthy, David Brooks, and Carole-Jean Wu. Carbon Dependencies in Datacenter Design and Management. ACM SIGENERGY Energy Informatics Review, volume 3, issue 3, pages 21–26. doi:10.1145/3630614.3630619 ↩︎
Kousik Nath. These are the numbers every computer engineer should know. freecodecamp.org, September 2019. Archived at perma.cc/RW73-36RL ↩︎
Joseph M. Hellerstein, Jose Faleiro, Joseph E. Gonzalez, Johann Schleier-Smith, Vikram Sreekanti, Alexey Tumanov, and Chenggang Wu. Serverless Computing: One Step Forward, Two Steps Back. At Conference on Innovative Data Systems Research (CIDR), January 2019. ↩︎
Frank McSherry, Michael Isard, and Derek G. Murray. Scalability! But at What COST? At 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎ ↩︎
Cindy Sridharan. Distributed Systems Observability: A Guide to Building Robust Systems. Report, O’Reilly Media, May 2018. Archived at perma.cc/M6JL-XKCM ↩︎
Charity Majors. Observability — A 3-Year Retrospective. thenewstack.io, August 2019. Archived at perma.cc/CG62-TJWL ↩︎
Benjamin H. Sigelman, Luiz André Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan, and Chandan Shanbhag. Dapper, a Large-Scale Distributed Systems Tracing Infrastructure. Google Technical Report dapper-2010-1, April 2010. Archived at perma.cc/K7KU-2TMH ↩︎
Rodrigo Laigner, Yongluan Zhou, Marcos Antonio Vaz Salles, Yijian Liu, and Marcos Kalinowski. Data management in microservices: State of the practice, challenges, and research directions. Proceedings of the VLDB Endowment, volume 14, issue 13, pages 3348–3361, September 2021. doi:10.14778/3484224.3484232 ↩︎
Jordan Tigani. Big Data is Dead. motherduck.com, February 2023. Archived at perma.cc/HT4Q-K77U ↩︎ ↩︎
Sam Newman. Building Microservices, second edition. O’Reilly Media, 2021. ISBN: 9781492034025 ↩︎ ↩︎
Chris Richardson. Microservices: Decomposing Applications for Deployability and Scalability. infoq.com, May 2014. Archived at perma.cc/CKN4-YEQ2 ↩︎
Mohammad Shahrad, Rodrigo Fonseca, Íñigo Goiri, Gohar Chaudhry, Paul Batum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, Ricardo Bianchini. Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider. At USENIX Annual Technical Conference (ATC), July 2020. ↩︎
Luiz André Barroso, Urs Hölzle, and Parthasarathy Ranganathan. The Datacenter as a Computer: Designing Warehouse-Scale Machines, third edition. Morgan & Claypool Synthesis Lectures on Computer Architecture, October 2018. doi:10.2200/S00874ED3V01Y201809CAC046 ↩︎ ↩︎
David Fiala, Frank Mueller, Christian Engelmann, Rolf Riesen, Kurt Ferreira, and Ron Brightwell. Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing,” at International Conference for High Performance Computing, Networking, Storage and Analysis (SC), November 2012. doi:10.1109/SC.2012.49 ↩︎
Anna Kornfeld Simpson, Adriana Szekeres, Jacob Nelson, and Irene Zhang. Securing RDMA for High-Performance Datacenter Storage Systems. At 12th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud), July 2020. ↩︎
Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armistead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie Germano, Anand Kanagala, Jeff Provost, Jason Simmons, Eiichi Tanda, Jim Wanderer, Urs Hölzle, Stephen Stuart, and Amin Vahdat. Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network. At Annual Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), August 2015. doi:10.1145/2785956.2787508 ↩︎
Glenn K. Lockwood. Hadoop’s Uncomfortable Fit in HPC. glennklockwood.blogspot.co.uk, May 2014. Archived at perma.cc/S8XX-Y67B ↩︎
Cathy O’Neil: Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown Publishing, 2016. ISBN: 9780553418811 ↩︎
Supreeth Shastri, Vinay Banakar, Melissa Wasserman, Arun Kumar, and Vijay Chidambaram. Understanding and Benchmarking the Impact of GDPR on Database Systems. Proceedings of the VLDB Endowment, volume 13, issue 7, pages 1064–1077, March 2020. doi:10.14778/3384345.3384354 ↩︎
Martin Fowler. Datensparsamkeit. martinfowler.com, December 2013. Archived at perma.cc/R9QX-CME6 ↩︎
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 (General Data Protection Regulation). Official Journal of the European Union L 119/1, May 2016. ↩︎